The state of identity
The early internet was built for anonymity
What began as an online community for a few dozen researchers is now accessible to an estimated 3 billion people. When it comes to building trust online, we’re still playing catch up.
A “dumb” core with intelligent edges
Long before viral cat videos, social media farms, and bitcoin, a team of government researchers was tasked with creating the world’s first computer network. The system was used primarily to exchange files and messages between a few dozen scientists. Identity verification was more of an afterthought; the network was still small and there wasn’t much of valuable on the network to steal at the time. These early internet pioneers weren’t concerned with who was online — they were just thrilled to be online.
Anonymity, speed, and ease of use drew people to the Internet. Usernames and passwords on different sites allowed for multiple, anonymous “digital identities” that existed completely separately from an individual’s “physical identity” as a real person in the world. This made it nearly impossible to match a username to an individual and vice versa.
The system was based on a “dumb” core that simply carried data, with intelligent edges — computers controlled by individuals. That meant it was (and still is) largely up to individuals to fend off fraudsters. “There’s this sense that the [Internet] provider’s not going to protect you,” Virginia Tech Historian Janet Abbate told The Washington Post. “The government’s not going to protect you. It’s kind of up to you to protect yourself.”
Soon, Internet users would blanket the globe
In the 1990s, partnerships with the telecommunication industry paved the way for commercialization of a new world-wide network. The number of people online skyrocketed — and so did the sensitivity of the data they were sharing. By 1998, with 147 million people on the web, the Internet had become a hub for financial transactions, allowing individuals to enter credit info and make purchases with the click of a mouse. “They thought they were inventing a classroom and it turned into a bank,” Abbate recounted.
PayPal, Ebay, and Amazon entered the scene. Just as quickly, scammers followed. By the early 2000s, phishers were already targeting PayPal customers by spoofing emails that would send them to lookalike sites to collect credit card information. Meanwhile, scams like the classic “Nigerian Prince” email became commonplace (in fact, it still rakes in over $700,000 a year). The Internet became a massive global network, still with no consistent way to verify identity.
Today, many of us do our banking, taxes, dating, job applications — even doctors appointments — completely online. Roughly 90% of all of the data online was created in the past 2 years. That’s 2.5 quintillion bytes of data every day, from over 3.7 billion people. Because we do so much online, our identity is more valuable than ever.
Yet, we’re more susceptible to identity fraud than ever
As the amount of highly-sensitive data shared on the Internet grows, it becomes increasingly susceptible (and valuable) to fraudsters. Yet the overall infrastructure to verify a person’s identity online has never been weaker. More and more companies are storing personal information with ineffective safeguards, and a single website breach can compromise individuals’ identities across the entire internet.
In short, the problem’s not getting any smaller: the 10 largest data breaches have all occurred since 2013 — the largest of which, Yahoo’s 2013 data breach, impacted 3 billion peoples’ data.
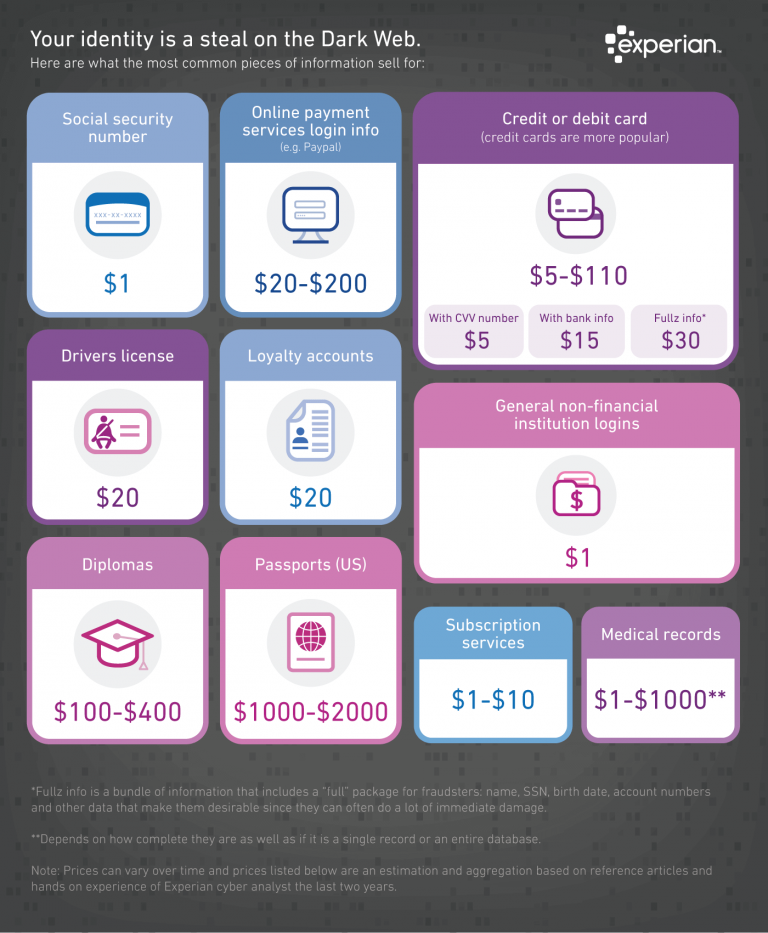
The recent breaches have pushed the price of personally identifiable information to an all-time low: hacked credit cards and CVV numbers sell for less than $5 on the dark web — Social Security numbers for as little as $1. It’s not a matter of whether a bad actor can obtain your personal info, but whether they decide to target you.
Even the US government, which often relies on companies like Equifax to conduct “remote identity proofing,” struggles to securely verify people online for their most sensitive systems, such as our Social Security portal and other applications for government aid. In a recent announcement, the US Government Accountability Office acknowledged large gaps in verification capabilities and pled for standardization in the space.
The Insurance Information Institute estimates that identity fraud cost individuals more than $16.8 billion in 2017 alone. Yet while the stakes higher than ever, our measures for protecting people remain woefully antiquated and our methods of identity verification are largely reactive.
The identity arms race
Since its inception, companies and government agencies alike have tried to build a more secure internet. Most measures have been “quick fixes” and almost all continue to rely on the end-user to protect themselves.
We are living in a post-SSN world
“I feel very strongly that the Social Security number has outlived its usefulness,” Rob Joyce, the White House’s cybersecurity coordinator said following the 2017 Equifax breach, which exposed over 145.5 million Social Security numbers.
The Social Security number (SSN) was never meant to be a unique identifier, though at one point it was considered the most secure way of verifying yourself online. From the beginning, using SSNs for identity verification was plagued by mishaps: when they were first issued in the 1930s, many people had them tattooed on their arms to keep them handy, and a popular wallet that included a placeholder social security card led thousands of confused citizens to think the sample number was their own.

Retrofitting this near century-old system to secure a highly-complex, ever-changing technology like the Internet was like trying to put reins on a spaceship. It created a single point of failure, relying on individuals to safeguard their unique number while simultaneously requiring them to use it for everything from buying a car to opening a credit card. When the system did fail, it failed spectacularly: the 2017 Equifax breach exposed nearly half of the US population’s SSNs, along with addresses, phone numbers, driver's licenses, and credit cards. Today, the SSN has been all but dismissed as a valid method of identity verification.
Knowledge-based verification was introduced… then broken
For increased assurance, banks would verify individuals by asking detailed personal questions based on credit reports and other data sources. These might be pre-chosen “static” security questions (like the name of your first pet) or randomized “dynamic” questions (like your current address) based on public records, private data, or transaction history.
Unfortunately, the knowledge-based authentication question for one site often relies on information exposed in the breach of another site. Once fraudsters have access to the same personal information as the real individual, this kind of information no longer serves to securely identify the individual.
Photoshop has made document verification difficult
Physical forms of identification like driver's licenses and government IDs attempt to bridge the gap between an individual’s digital and physical identity. However, widely accessible image manipulation software like Photoshop can be used to doctor and manufacture fraudulent documents. Moreover, the millions of driver’s license numbers exposed in the Equifax breach alone can be used to write checks in an individual’s name or to forge new licenses.
It’s a constant race to outsmart bad actors
As authorities race to create new technologies and methods to verify people online, thieves and even nations will race to bypass and crack new verification methods. Facial recognition and document scanning are some of the latest identity verification technologies, but it’s only a matter of time before hackers catch up. Socially sanctioned data collection in the form of viral Buzzfeed quizzes and face swap apps open the door to hacks in the future. Even institutions like Equifax don’t take identity verification seriously until something goes terribly wrong. So why aren’t companies more proactive about preventing cyberattacks in the first place?
Deepfakes and the future of fraud
Deepfakes, which are image, video, or audio representations of people seemingly doing or saying things they’ve never actually done or said, already have the Pentagon scrambling. By playing on the natural human tendency to trust people we’re familiar with, deepfakes make it possible for attackers to fly under the radar — often until it’s too late.
While there are some characteristics that can give away deepfakes — such as odd lighting reflections, fuzzy edges around images, or strange color gradients — companies need solutions capable of detecting these images on-demand to prevent unauthorized access.
Identity is fragmented
It takes a lot of resources to verify identity on the internet, and best practices are constantly evolving.
There are hundreds of new point solutions to verify identity
Proprietary data owned by single corporations can only address a few facets of identity, and vendors are constantly rolling out their own solutions that incorporate new signals in lieu of those that have been compromised.
Some vendors claim that scraping even more information about an individual, whether from social media sites, emails, and other public sources, is the best method for verification. Meanwhile, others tout ever more sophisticated (and sometimes convoluted) checks for liveness. With options ranging from eye analysis to smile comparison to face scan under multiple light settings, companies are often at a loss to separate the signal from the noise.
Behaviors like typing style and voice inflection can indeed identify individuals based on the unique way they interact with their devices. High-security industries like online banking and e-commerce have already begun to use voice identification for fraud prevention, spurring the growth of a $3.9 billion behavioral biometrics market by 2025. AI image processing software can be used to detect photoshopped or computer-manipulated documents for verification, and “re-verification” solutions can even run in the background during a handful of normal online interactions.
Although every vendor lauds their product as the end-all verification solution, the truth is that each of these verification types comes with their particular tradeoffs, and companies must weigh the importance of user friction vs. security, device availability vs. robustness, or international coverage vs. single country expertise. The dizzying rate at which new third-party solutions and patches are created (and old ones are rendered obsolete) makes it difficult — and unprofitable — for companies to keep up.
Every business is different
Each business has its own needs, and within a single business, there may be multiple use cases that require different identity solutions. For example, a food delivery platform will have a different onboarding and verification process for its couriers than its customers, and a fintech startup may need to collect a ton of identity data from a individual to issue a $100k loan but far less to open a basic checking account. A single individual may also have different touchpoints with a company throughout their experience: that same courier may need to go through different identity checkpoints during sign-up than during account recovery.
In short, there’s no such thing as a “silver bullet” identity solution. Instead, big companies often stitch together hundreds of out-of-the-box identity verification solutions. PayPal uses hundreds of third-party identity vendors, Facebook uses a mix of in-house human moderators and 3rd party companies, and Microsoft employs a fearsome in-house cybersecurity and fraud detection team called DART ( “Detection and Response Team”).
Unfortunately, not all companies have the resources to cobble together a solution that’s perfect for them. And, even for companies that do, identity verification isn’t a revenue driver and therefore it isn’t a priority. “In the real world, people only invest money to solve real problems, as opposed to hypothetical ones,” Dan S. Wallach, a Rice University computer science professor who studies online threats told The Washington Post.
One of the biggest mistakes companies make is assuming they have or need a single perfect tailored verification solution. In a space as dynamic as identity, with constantly changing regulations and verification methods, companies that build their own tools find themselves investing more and more resources to stay on top of industry trends.
Data isn’t just an asset… it’s a liability
In 2019, the FTC charged Equifax and Facebook $700 million and $5 billion in fines respectively for mishandling individuals’ data, blowing the previous record (a $148 million fine for Uber’s 2016 data breach) out of the water. Increasing federal and consumer pressure means the PayPals and Facebooks of the world now allocate billions of dollars a year to protect their identity information: Facebook will spend $3.7 billion on safety and security in 2019 — as much as their pre-IPO revenue.
Even with a massive budget, an ineffective or clunky verification system can jeopardize customer loyalty and brand value. The Harvard Business Review found that a 10 second delay on a transaction can cause 50% of users to abandon the page, and 30% of enterprise revenue is at risk due to poor data quality (for example, when people give false answers to breeze through long-winded forms). Frequent “Making sure it’s you” pop-ups, day-long delays waiting for a test fund to transfer, and limited integrations with popular third-party apps only add to this frustration. All of this makes customization and adaptability crucial to meet customer expectations and mitigate the risk of identity fraud.
Combating fraud moving forward
Moving forward, companies need to defend against fraud by taking a more proactive approach that depends on three key components: artificial intelligence (AI), automation, and accelerated approval.
Artificial intelligence
AI makes it possible to increase the accuracy of digital identity verification and in turn reduce the overall risk of fraud. By training AI and machine learning algorithms to detect discrepancies in identity documents in real time, businesses can better comply with regulations such as GDPR, The California Consumer Privacy Act (CCPA), Know Your Customer (KYC), and Anti-Money Laundering (AML).
Automation
Automation is also critical for online verification to succeed at scale. As both user and data volumes increase, companies need ways to keep pace without sacrificing accuracy or security. Automated ID verification enables businesses to quickly and accurately verify ID documents anywhere, anytime.
Accelerated approval
While battling fraud, companies must also consider the customer experience. If the verification process is too complex and cumbersome, customers may take their business elsewhere. As a result, businesses need digital solutions that make it quick and easy for customers to get verified.
The future of identity depends on the business and individual
Businesses will need solutions that meet customer expectations for each unique use case.
Businesses need partners that adapt to their business, not the other way around
Rather than stick with a single point solution, businesses need to be more intentional about what exactly they need to verify and how much personal data they need to store. Does it make sense for an e-commerce store to save a driver’s license and introduce the unnecessary risk of data leakage when all they need to do is verify age? Probably not. Does it make sense to have a static verification flow for every single use case from onboarding new users to verifying during password reset attempts? Maybe. What is certain is that businesses have unique requirements, and identity solutions need to be robust enough to meet their needs no matter the use-case, industry, or regulation.
Context is key
Who an individual is in the real world will play a large role in future identity solutions. Has your data leaked five times already? Are you a celebrity or public figure? Are you verifying your identity from a foreign IP address? The verification process you go through should be more robust. Analysts predict that more solutions will incorporate an individual’s behavior, merging our physical and digital identities to create a safe, frictionless experience.
Identity will be more holistic and accessible
Identity checkpoints will depend on what you are trying to do, who you are, and where you are doing it from. Importantly, it will tie together multiple forms of identity verification to create a fluid solution that adapts to the interaction and the individual involved.
Companies are no longer limited to simple checks such as performing a database lookup to verify if an individual with a name, date of birth, and address exist. Active checks such as reverse phone number lookups and real-time document scanning can work in conjunction with passive signals such as network checks, TOR/VPN detection, browser analysis, and more so that companies can be assured that an individual is truly who they claim to be.
Ultimately, more ways to verify means more access to resources and platforms for people around the world. At Persona, our mission is to do what quick-fix security measures to date have not: give individuals access to a fast, frictionless identity verification experience, without putting them — or businesses — at risk.
If you’re interested in learning more about our work on identity, reach out to us at info@withpersona.com.
FAQs
How can businesses prioritize digital identity?
Toggle description visibility
Prioritizing digital identity starts with making it a key component of customer onboarding — and beyond. By implementing a holistic approach to identity, organizations can reduce their overall fraud risk.
Why is digital identity critical for ongoing success?
Toggle description visibility
Digital identity forms the core of online activities, from ecommerce purchases to financial transactions to user account creation. As a result, robust and reliable identity verification is critical to both boost consumer confidence and ensure that business operations align with evolving compliance expectations.