7 things I learned from building Persona’s Graph product
As a main contributor to Persona’s Graph product in the early days, I am incredibly proud to share we hit our revenue goals for 2024 just halfway through the year! And now that we’re 18 months post-launch, I can’t help but be grateful for such an incredible journey.
But the work is not done — as we work on evolving Graph to the next level, I find myself leaning heavily on the principles I learned while building this complex product. I’d like to outline them here and invite anyone reading to discuss what it takes to do great engineering and product. If this resonates with you, we are hiring and would love to see you on our team. 🙂
First, a little background: I joined Persona as a full-stack engineer relatively early in my career. I had no background in identity verification or graphs, but I had a big appetite for seeing what it’d be like to build a great product from scratch. Our co-founders Rick and Charles invested into building out a POC for a new product idea, and I spent the next year being the main engineer for Graph as well as driving the product direction, managing our beta customer relationships, and wearing many other hats.
Graph is the first-of-its-kind fraud investigation and link analysis tool that pairs identity data with sophisticated link analysis to help fraud and compliance teams catch more bad actors efficiently and stop fraud before it happens via proactive blocking. This enables businesses to uncover and block hard-to-catch fraud incidents before they happen — and quickly adapt their fraud strategy against repeat offenders.
With that background set, let’s move on to the learnings:
1. Choose the right database and vendor.
We originally tried building Graph on a traditional relational database because 1) it didn’t take much to get up and running and 2) we already had the expertise. However, it didn’t allow us to accommodate flexible data types or iterate quickly on types of graph traversal algorithms.
Plus, it wasn’t fast enough — we knew it’d be crucial to have flexible schemas and fast response times on millions of nodes of data. It needed to run complex graph algorithms immediate enough for customers to make decisions in real time. Without that, Graph would just be a pretty tool to explore relationship visualizations after the fact.
After exploring different database technologies, we picked an up-and-coming graph database vendor. It required some initial investment, such as learning the domain-specific language and thinking about data traversal in a very different way. There were also other risks with this. With any relatively new technology, performance and bugs may not be rigorously tested yet. The tooling isn’t that strong yet, so there are fewer options for scaling, integration, and creating data pipelines. And there is a lack of expertise — when you run into problems, there are few experts to turn to.
Fortunately, our graph database vendor was responsive — a quality we needed as we were writing specialized graph algorithms where generic public documentation and use cases wouldn’t suffice. We ended up meeting with their team bi-weekly to get recommendations on how to write the most performant traversal algorithms, maintain high availability, and handle real-time data syncing.
Ultimately, this investment has enabled us to handle billions of data points and flexible customer requirements — and we’re currently working toward sub-10ms response times. It is Graph’s superpower to process large numbers of relationships in real time to make immediate decisions.
2. Model for the next largest context.
Our first data schema looked something like this:
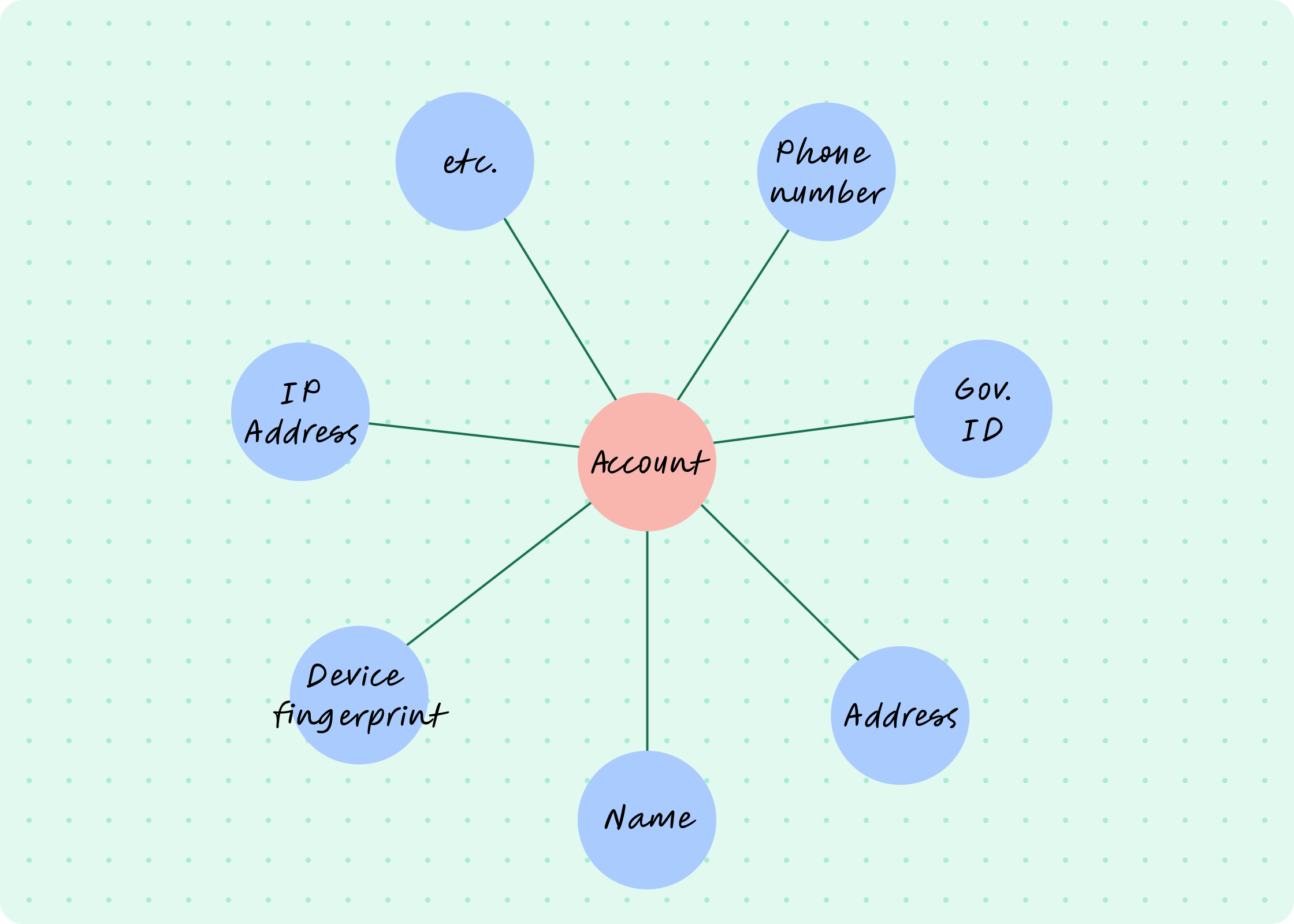
This first iteration had a collection of fixed node types (name, address, phone number), and it worked great for a while. However, customers soon realized that the more data they had in Persona, the more insights from Graph they would have. With this flywheel going, we had lots of requests to process graph relationships for custom data collected outside of Persona, too. With that, the data schema would look like this:
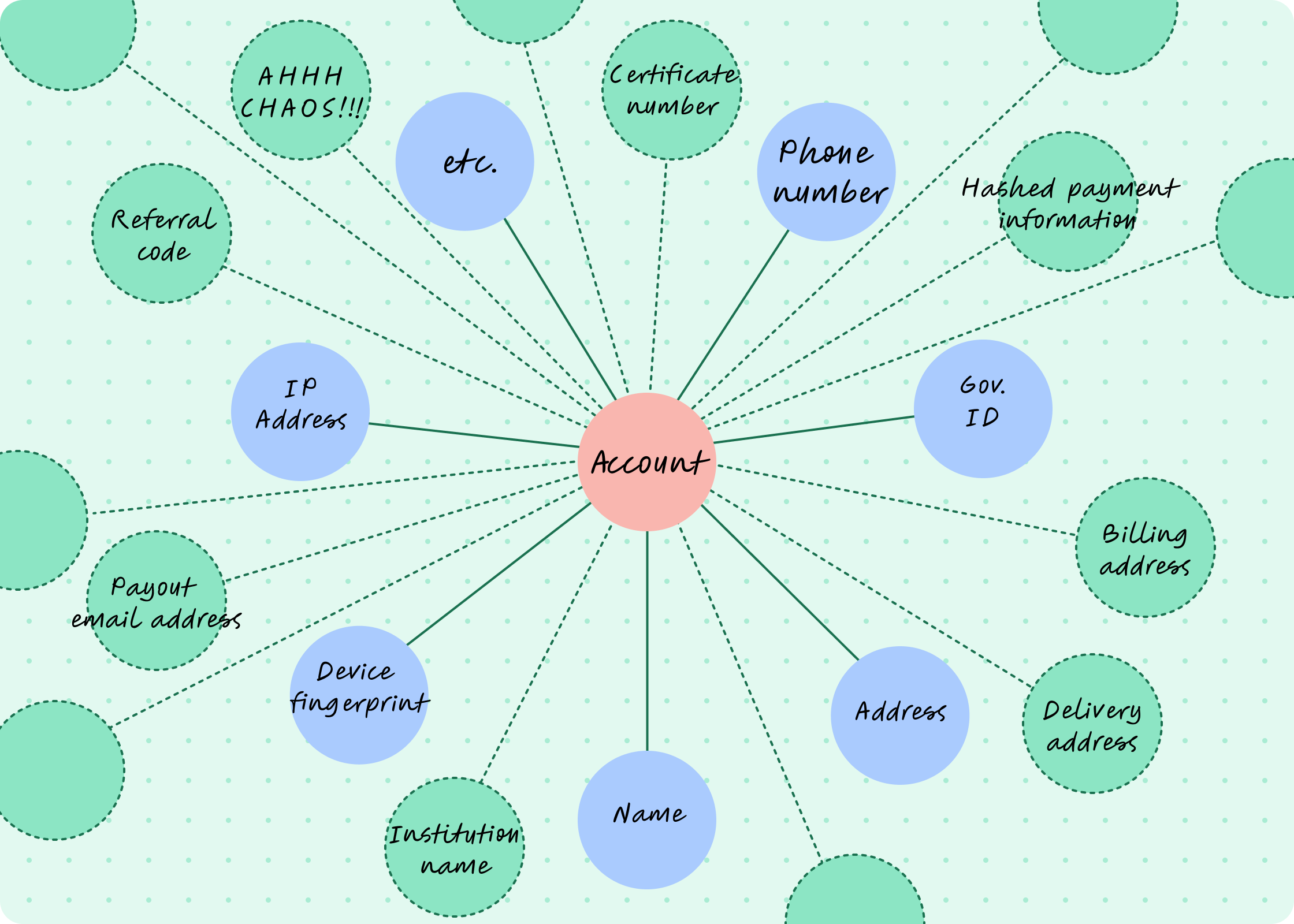
Needless to say, this was cluttered and unsustainable. We couldn’t evolve fast enough to meet unique customer data demands and instead had to do a lot of one-off data pipelines and integrations.
We took a step back and during our big rebuild, my teammate Kerry Xing evolved the schema to something like this:
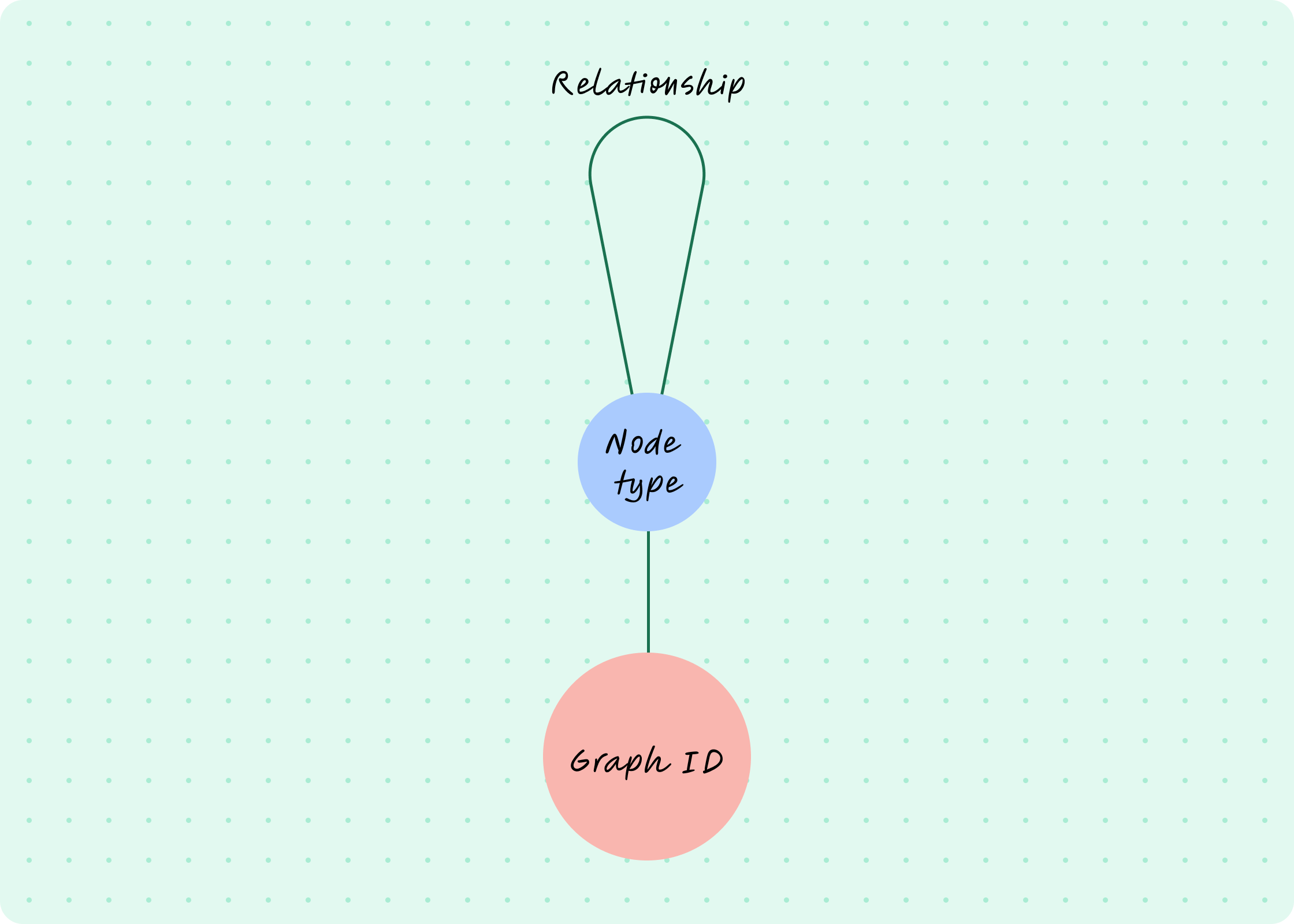
Now, we could have nested relationships, an unlimited number of node types without custom backfills and data pipelines, a set of graph algorithms that work across the board, and an easier-to-understand schema. The types of diverse use cases we could now support without much engineering effort skyrocketed after that, and we’ve never looked back.
This principle also applies to how we designed our product. We have a strong platform at Persona — there are a lot of synergies between our products like Cases, Workflows, etc. There are a myriad of ways Graph builds on top of data collection from Dynamic Flow, actions from Workflows, and the rich review interface from Cases. It would be easy to continue leaning on these synergies, but we knew long term we wanted Graph to be an entry point to Persona on its own. Our investment in Graph as a standalone product has forced us to think more broadly and stand out from other graph solutions on the market.
3. Early on, do everything in the service of delivery.
When we first decided to invest in Graph as an experiment, there were so many open questions around where we could take the product. What actions should we build that feel powerful, but don’t overly complicate? How do we strike a balance between visual and textual representations of data? What should normalization and data cleanup look like? Any of these questions could easily fuel hours of discussion. And these long meetings would often leave us with more open decision points than where we began.
I would scour product blogs, research analogous features in other products, and pitch ideas to mentors — but in the end, what really gave us clarity was getting working features in front of our customers and seeing what they thought. Turns out, even describing a potential feature and asking if it resonates with them often wasn’t useful. Sometimes, it ended up confusing us as well. Many customers were not familiar with link analysis, so something might not sound useful until they actually saw it in action. There also weren’t many other graph products on the market that were doing what we wanted to do, making it hard to draw comparisons when the features were made for different contexts.
One of the key things that accelerated delivery velocity (and subsequently product insight) was identifying the main bottlenecks in service of delivery — and innovating around them. First, we built out a rapid way of importing specific schemas and custom data. Even without the full data pipeline built out, we could rapidly build out demos for vastly different customer profiles. One customer might be looking to flag promotion abuse from fraudulent profiles with similar email addresses, and the next customer might want to find patterns in transactions between businesses.
Lastly, regular share-outs with the sales and post-sales teams helped tremendously. When features weren’t finalized, it could feel a bit premature to run trainings and write integration docs. However, these customer-facing teams were stellar partners for quickly integrating beta features for our customers and served as our eyes and ears for potential new opportunities.
Don’t get caught up with making the best possible decision when that time can be better spent executing and iterating. You can avoid a lot of the burnout that comes with slow progress and no visibility into whether you’re expending effort on the right things.
4. When needed, get your hands dirty building custom front end.
This probably doesn’t apply for every product, but when your product that relies on rich visualization, it is essential to have a powerful and dynamic look and feel. We experimented with several different force-directed graph libraries, chose one, and later rewrote our graph behaviors using another because it allowed for more customization.
However, the built-in functionality for things like an undo/redo stack, group collapsing, and hover cards soon became inadequate for the type of rich interactions we wanted to support. I was initially hesitant, but our team paved the way for building custom event handling, components, and behaviors. We invested in building hot keys, a rich sidebar that mirrors canvas node states, customizable exportable data, layers that correspond to different canvas modes, and more. While this is more complexity for us to maintain, it also pushes us all to be better front-end engineers and doesn’t limit the features we dream up. It has since paid dividends because our Graph UI is one of the most common things our prospects compliment us on, and it helps us stand out from other competing products.
Again, if this interests you and you’d love to work on complex front-end interactions and states, we’d love to have you on our team. 😉 There is plenty of work across the full stack as well.
5. When at a stalemate, it helps to meet individually before coming together to make a decision.
When creating a novel product, it’s almost guaranteed that people will have differing strong opinions. At Persona, we like to keep our strong opinions loosely held — but that can still leave the team at a stalemate around which direction to try. My natural impulse to bring all stakeholders together and hash it out would sometimes spiral off topic, even with a well-intentioned agenda.
Eventually, I learned to rely on my instinct for decisions that could be contentious. By meeting individually with stakeholders and understanding their worries and vision ahead of time, I could get everyone on the same page and anticipate obstacles. That way, by the time the entire group met, we’d come in with a sophisticated understanding of the problem and what exactly needed to be decided now versus later — and more effectively make a decision.
6. Early on, index more on customer sentiment over number of customers.
We had a compelling demo for Graph that gave us a strong pipeline of beta customers early on. It was exhilarating seeing that lightbulb go off when customers realized how Graph could help them catch new kinds of fraud they wouldn’t have otherwise found and replace brittle manual querying. Their fraud teams went from asking data analysts for a weekly CSV of duplicate emails and names to using our Graph Explorer tool to see all new potential fraud rings from linkages between 10+ different pieces of data at a glance.
After a while, though, it felt like things were slowing down. I went from having a calendar full of customer pitches and followups to weeks where I’d go without one. I worried if we were doing enough to be considered a successful product to invest in long-term.
I distinctly remember recounting these worries to Rick. He recommended prioritizing a few super happy customers over many disengaged customers who our small team would struggle to solicit high-fidelity feedback from. Focusing on a few strong beta customer relationships ended up being invaluable. Having such close partnerships inspired us to build popular features like an array of Workflow actions, Graph snapshots, and more.
7. Don’t be afraid to rebuild and refactor with everything you’ve learned.
Graph V1 was very much an experiment that turned out to be a success. We built it rapidly and iterated rapidly with customer feedback, but it soon became clear we couldn’t easily build some features customers wanted. Some feature requests were too dynamic for our models. For example, we could only display data that Persona collected, rather than a rich store of data that the customer might have accumulated before they started on our platform. Other feature requests couldn’t easily be added to the limited screen real estate we had in our first UI design. We could only offer a limited set of bulk actions on the bad actors in a fraud ring.
We initially made do by hacking some solutions together, but eventually made the hard choice to rebuild with everything we’ve learned! It was a difficult decision that took double the amount of time we originally thought it would, but ultimately it shows that even with paying customers and an established product, we are continually evolving and committed to long-term product excellence. Today, we can support more diverse use cases, snappier performance, and powerful investigation tools than we could’ve ever originally imagined.
I sincerely hope these lessons show you how one engineer can have a big impact on the growth or success of a whole product line, and how if there’s interest, you can take on many different roles here at Persona.
Thank you to all of the hardworking Graphnerds, Salesnerds, PostSalesNerds, and the many many other people who I’ve bounced ideas off of for Graph. You all have helped us get to where we are today and undoubtedly will also play a key part in our ambitious plans for the future.
Thanks for reading! I’m eager to hear your thoughts. 💜,
Jes